
In heel veel handboeken of digitaliseringsplannen komen zinnen voor als:
De norm bij deze controle is bepaald op 96%. We accepteren dat per dag 8 documenten (4%) niet goed gescand zijn en opnieuw gescand moeten worden.Los van het feit dat hier relatieve en absolute aantallen door elkaar gebruikt wordt, is de vraag natuurlijk: wat gebeurt er als er een negende fout gevonden wordt? En hoe wordt vastgesteld dat niet meer dan 4% van de registraties fout zijn, hoeveel documenten worden gecontroleerd om dit vast te stellen?
Het Stadsarchief Amsterdam schrijft in zijn verder uitstekende Aanbevelingen voor digitalisering van tekstdocumenten ten behoeve van het concern Amsterdam (pdf):
Het is daarbij zinvol om de controleprocedure op papier te zetten en voor de verschillende kwaliteitseisen foutmarges te hanteren.Op deze zin volgt een uitgebreide en gedetailleerde beschrijving van de manier waarop allerlei aspecten gecontroleerd zouden kunnen worden. Maar het vaststellen van de "foutmarges" wordt niet nader toegelicht.
In de richtlijnen van het Geheugen van Nederland staat onder 2.1 Steekproef:
Van een batch wordt 10% getest. Als meer dan 1% van de batch niet voldoet aan de normen (op basis van de onderstaande kwaliteitseisen), dan wordt de batch teruggezonden. De batch wordt dan in het geheel nagelopen en waar nodig verbeterd. Als minder dan 1% van de batch fouten vertoont, worden alleen de foute afbeeldingen teruggezonden en verbeterd. Als de batch terugkeert zal opnieuw een controle worden uitgevoerd. Gaat het om 10.000 stuks dan worden er 1000 bekeken. De 10.000 voorwerpen worden in 10 batches van 1000 verdeeld. Uit elke batch worden er 100 bekeken. Gaat het om de eerste batch dan wordt afbeelding 50 tot 150 bekeken.Dat ziet er al iets beter uit, maar in dit voorbeeld wordt er dus van uit gegaan dat ongeacht het aantal te controleren eenheden het controleren van 10% daarvan goed genoeg is. (De richtlijnen worden momenteel aangepast, dus misschien is dit in de nieuwe versie ook wel veranderd.)
Nog een laatste voorbeeld:
Het probleem hierbij is dat de absolute aantallen waar het om gaat, te klein zijn. De verwachting is dat er in totaal ongeveer 5.000 documenten per maand geregistreerd worden. Dat betekent dus dat er 50 documenten gecontroleerd worden en dat er maar één registratie fout mag zijn.
Naam proces Beoordelen ingekomen (analoge) post Controlecriteria (+ normering) Keuze juiste DSP-proces (98% juist) Uitvoering controle Maandelijks representatieve steekproef van minimaal één procent van de ingekomen documenten
Hoe zou het dan wel moeten? Daar is een norm voor!
Om te beginnen dit: 100% controle heeft weinig tot geen zin en geeft alleen de schijn van volmaaktheid. Je weet namelijk nooit hoeveel fouten bij het controleren gemaakt worden.
Om dit tegen te gaan heeft het Amerikaanse leger in 1950 een statistische methode ontwikkeld: Acceptable Quality Level. Hier vind je de ‘originele’ norm (pdf).
Hoewel ik geen statisticus ben (verre van dat zelfs), ga ik hieronder toch proberen die AQL-methode uit te leggen, in de hoop dat er in de toekomst wat beter gekeken wordt naar de toepassing van steekproeven om onder andere scan-opdrachten te controleren.
AQL
De opzet van de kwaliteitscontrole is afhankelijk van verschillende factoren:
- Geaccepteerd Kwaliteitsniveau
- Bestandsomvang
- Controleniveau
- Goed- en afkeuren
- Steekproefplan
Dit is het laagste kwaliteitsniveau dat gemiddeld genomen geaccepteerd wordt. Bijvoorbeeld: in 1% van de aangeleverde documenten mogen fouten zitten. (Dit betekent overigens NIET dat de leverancier bewust ‘foute’ documenten mag aanleveren.)
Controleniveaus
De norm onderscheidt drie verschillende controleniveaus: I, II en III. Hierbij is II het standaard controleniveau. I is voor het versoepelde controleniveau en III geldt voor verscherpte controles.
Het idee achter het systeem is dat een leverancier ‘krediet’ kan opbouwen, waardoor de afnemer minder strikt kan of juist strikter moet gaan controleren. Meestal wordt hierbij van het volgende uitgegaan:
- Start: controleniveau II
- Van normale naar verscherpte controle: Wanneer 2 van 5 opeenvolgende batches worden afgekeurd.
- Van verscherpte naar normale controle: Wanneer 5 opeenvolgende batches zijn goedgekeurd.
- Van normale neer versoepelde controle: Wanneer
- de 10 voorgaande batches zijn goedgekeurd EN
- het totaal aantal fouten uit de voorgaande 10 batches kleiner is dan het van toepassing zijnde aantal uit tabel VIII uit de norm
- Van versoepelde naar normale controle: Wanneer een batch wordt afgekeurd.
Er worden ook nog drie "speciale" controleniveaus beschreven, maar die zijn voor nu even niet relevant.
Bestandsomvang / batch
Dit is het totale aantal geproduceerde / geleverde items waarvan de kwaliteit vastgesteld moet worden. Meestal zal van iedere batch die geleverd wordt, een bepaalde kwaliteit geëist worden.
Bijvoorbeeld: Een leverancier levert één keer in de week circa 5.000 gescande documenten. In de norm wordt aan iedere bestandsomvang een aparte letter toegekend. In het schema hieronder staan de kenletters voor de drie normale controleniveaus en de drie speciale niveaus:
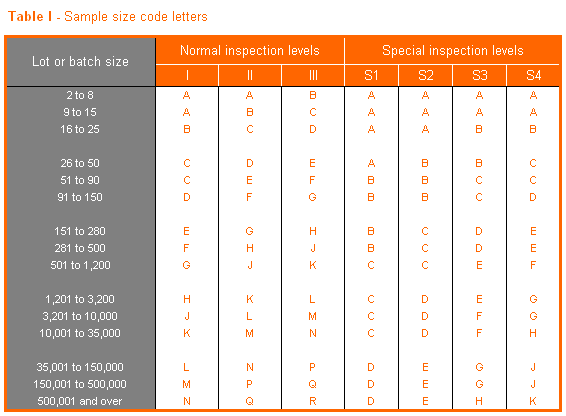
Aan de hand van de kenletter kan dan in onderstaande tabel de steekproefomvang vastgesteld worden.

Goedkeuren of afkeuren
Een batch wordt goed gekeurd als het aantal fouten kleiner is dan het maximaal toegestane aantal fouten uit Tabel 2. De geconstateerde fouten dienen overigens wel gecorrigeerd te worden door de leverancier.
Wanneer het aantal fouten de maximumwaarde overschrijdt, wordt de hele batch afgekeurd en moet de leverancier deze helemaal opnieuw aanleveren. De batch wordt dan opnieuw, op dezelfde manier gecontroleerd.
Als je van een geaccepteerd kwaliteitsniveau van 1% uitgaat,dat in dit voorbeeld dat er van de 200 items maximaal vijf fout mogen zijn. Zodra de zesde fout geconstateerd wordt, wordt de hele batch afgekeurd.
Kwaliteit van de batch
Bij het vaststellen van een controleprotocol moet altijd de vraag zijn: hoeveel fouten accepteer ik? Maar, de vraag is ook: Hoe groot is de kans dat ik met mijn controleprotocol te veel foute items "doorlaat"? Dit is met behulp van de "Operating Characteristics" uit de norm vast te stellen.
In het voorbeeld hierboven ging ik uit van een batchomvang conform Kenletter L en een (gemiddeld) geaccepteerd kwaliteitsniveau van 1%. Maar hoe groot is nu de kans dat een batch met 3% fouten ten onrechte wordt goedkeurd?

Steekproeven ja, maar wel goed
Het nemen van steekproeven kan een goede manier zijn om de gemiddelde kwaliteit van scans te controleren. Maar dan moet je niet 'zo maar' een steekproef nemen en 'zo maar' een foutenmarge kiezen. Met behulp van de AQL is het mogelijk om een weloverwogen steekproef te nemen die ook iets zinnigs zegt over de kwaliteit van de hele batch. En hoewel het in eerste instantie ingewikkeld lijkt, hoop ik dat hiermee duidelijk geworden is, dat dat reuze meevalt.
Afbeeldingen
Quality Street van Nataliej
Table I
{kind=link}
Table II
{kind=link}
Ingmar,
BeantwoordenVerwijderenEen buitengemeen goed en vooral bruikbaar stuk. De enige vraag die bij mij opkomt bij het lezen is wat er bij een machtigingsaanvraag nou een geaccepteerd percentage is. Uit jouw stuk lijkt het een beetje alsof 1% een acceptabel niveau is. Dat is misschien ook wel waar wanneer je alle mogelijke fouten bij elkaar optelt, dus kritische en non kritische fouten!
Waar ik voor zou pleiten is een tweedeling waarbij onderscheid wordt gemaakt tussen kritische fouten (een document is na conversie niet of niet geheel meer leesbaar) en non kritische fouten, bijvoorbeeld niet alle metadata is correct ingevuld of de gescande image staat eigenlijk een beetje te scheef maar is nog wel geheel leesbaar.
In mijn optiek zou je voor kritische fouten strenger moeten zijn, bijvoorbeeld 3 promille en voor non-kritische fouten ruimhartiger, bijvoorbeeld 3 tot 5 %
Leon,
BeantwoordenVerwijderenDie 1% is een willekeurig voorbeeld en is niet het geaccepteerd percentage dat de Archiefinspectie hanteert bij vervangingsaanvragen.
Het klinkt flauw, maar wij zijn niet degene die last hebben van een hoog geaccepteerd foutenpercentage. Mede daarom hebben wij geen minimale norm geformuleerd in de Beleidsregel en zullen dat ook niet doen, denk ik. Uitgangspunt is dat degene die vervangt aangeeft wat hij als minimale kwaliteit accepteert en beargumenteert hoe hij denkt die kwaliteit te realiseren. Ik kan me wel voorstellen dat we in de beleidsregel een verwijzing naar de AQL gaan opnemen als "steekproef-methode" maar ook dan geldt: als je het anders doet en je kunt aantonen dat het resultaat gelijkis, dan mag dat ook.
Goed verhaal dit! Schandelijk genoeg ken ik deze methode niet.
BeantwoordenVerwijderenLeon heeft een punt: de ene fout, is de andere niet. Dat is precies het meest lastige punt van kwaliteitscontrole: want wat zijn nu daadwerkelijk de kritische fouten? En: wil je een dergelijk onderscheid tussen kritische en minder kritische fouten in je methode meenemen dan heb je de kans dat je kwaliteitscontrole procedure een bureaucratisch monstrum wordt. Hoe dit te voorkomen?
Het zou geen kwaad kunnen over dit onderwerp eens iets te organiseren - een studiemiddag? Misschien juist met mensen van buiten de "sector".
Dank je wel Robert. Zo'n studiemiddag lijkt me wel zinvol en interessant.
BeantwoordenVerwijderenLeon en Robert vragen zich alletwee af of je een onderscheid zou moeten maken tussen lichte en zware fouten. Op dit moment heb ik een Handboek Vervanging onderhanden waar dit al in gebeurt. Daarin worden voor verschillende typen fouten, ook verschillende kwaliteitsniveaus gehanteerd: de keuze tussen wel/niet registreren mag in 5% van de gevallen fout gaan, terwijl de keuze tussen bestaande of nieuwe zaak maar in 2% van de gevallen fout mag gaan.
BeantwoordenVerwijderen(Ze hanteren nog niet AQL, maar het was wel de aanleiding om dit stukje nu maar eens online te zetten.)
Zoals ik hun werkwijze interpreteer testen ze op ieder criterium apart en gooien ze dat niet op één hoop. Dit betekent dus veel werk (en misschien wel verschillende steekproeven nemen uit dezelfde batch), maar ik weet niet hoe ze dit gaan organiseren.
Ik weet ook niet hoe je dit het handigste kunt organiseren...
Als je gaat organiseren Robert, ben ik daar graag bij :)
BeantwoordenVerwijderenIngmar, sympathie voor je poging om de wereld van cijfers en kansen te doorgronden, ook wel eens met je geformuleerde kritiek op foutenmarges e.d. Maar toch een ? bij de aangedragen oplossing. Is het niet verstandiger de foutenmarge los te laten op het aantal gedigitaliseerde archieven i.p.v. de margediscussie te openen in gedigitaliseerde archieven. Ik heb toch het gevoel dat we dan stuivers aan het poetsen zijn, terwijl we in deze overgangsperiode van analoog naar digitaal het aantal incidenten willen reduceren. Daar past een overall aanpak beter dan een kurketrekker methode. Dan is vervolgens de vraag meten we per archiefbewaarplaats of landelijk of kleinere eenheden? Kom je al snel op de berusting: "het is goed dat we kijken naar marges, maar wat lost het op en wie dienen we er mee?". Dus wellicht moeten we vooraf vaststellen dat 50% van wat goed had moeten zijn fout zal zijn. Zolang we maar niet formuleren wat 100% is de 50% de 100% en doen we alles goed (of fout als je deze redenering aanhangt) waamee maar weer bewezen is dat er sprake is van een aflopende reeks van betrouwbaarheid bij: rechters, misdadigers en ....rekenmeesters.
BeantwoordenVerwijderenGroeten Max
Leon, zie ik het nu goed dat de steekproefomvang toch een vast percentage van de te controleren omvang is (eerst 2%, daarna 5%)?
BeantwoordenVerwijderen@Max Hoewel ik mijn stukje begin met een verwijzing naar de machtiging vervanging, was het niet mijn bedoeling om enkel daar iets over te zeggen. Het gaat mij ook niet per sé om het beperken van het aantal fouten. Mijn punt is algemener: als je iets aanschaft en je eist van de leverancier dat hij een bepaalde kwaliteit levert, hoe verifieer ik dan of de geleverde kwaliteit aan de eisen voldoet?
BeantwoordenVerwijderenDat geldt voor het scannen van akten van de burgerlijke stand, het digitaliseren van foto's, maar misschien ook wel voor het ordenen van documenten en dossiers.
Ik zie nu gebeuren dat er voor veel geld opdracht gegeven wordt om bijvoorbeeld kranten te laten digitaliseren, zonder dat ook maar geprobeerd wordt om vast te stellen of de leverancier zijn werk goed (genoeg) doet. "Ach ze zijn daar zo deskundig, dat gaat wel goed...")
Het gaat dus niet om het poetsen van stuivers, maar meer om bewust omgaan met de beperkte hoeveelheid beschikbare stuivers en goed opdrachtgeverschap.
Ingmar, het criterium zal aantallen zijn, Bij een dagproductie van 30 documenten scannen op een kleine DIV afdeling is het overdreven een specifiek controlesysteem op te zetten, rekening houdend met een vast percentage, je zult daar in meeste gevallen een één op één controle houden.
BeantwoordenVerwijderenBij grotere aantallen echter is het van groot belang om te weten wat je meet en ook moet kunnen aangeven hoe relevant een steekproef is. dat kan alleen met percentages, want die zijn meetbaar en in een systeem vast te leggen.
Wat ik zo mooi vind aan het systeem in jouw blog is vervolgens dat je het percentage kan laten afhangen en kunt aanpassen aan het controleniveau dat van belang wordt geacht. Oftewel er wordt dan ook nog rekening gehouden met de staat van dienst van de uitvoerder (ongeacht of dat nu een externe partij is of niet) en er kan rekening gehouden worden met het belang van de gescande informatie voor de organisatie.
Maar 'mijn' systeem gaat (op het oog) just niet uit van percentages. Als je 30 items (niveau II, codeletter D) wil controleren, kun je volstaan met een steekproef van 8 items = 27%.
BeantwoordenVerwijderenAls je 30.000 items moet controleren (niveau II, codeletter M) moet je 315 items controleren = 1%
"Jouw" systeem gaat uit van relevantie en fouttolerantie. Impliciet wordt er per definitie gewerkt met een vaste verhouding tussen de grootte van de geproduceerde hoeveelheden en de grootte van de te nemen steekproef. Het is andersom benaderd, maar uiteindelijk zou je dit ook in percentages kunnen aangeven zonder het systeem geweld aan te doen.
BeantwoordenVerwijderenHoe dan ook, ik stel de aantallen in de tabellen ook niet ter discussie, althans niet zonder deze methodiek in de praktijk getest te hebben. Mij ging het er vooral om dat er differentiatie wordt aangebracht op de waarnemingen. Niet alleen om daardoor een betere en meer afgewogen goed- of afkeuring te verkrijgen, maar ook om op basis van trends het algemene kwaliteitsniveau te kunnen beoordelen en daarna te beïnvloeden. Immers als steevast uit controles blijkt dat pagina's na scanning vaak meer dan 2 graden afwijken kan dit een indicatie zijn dat de gebruikte scanner onderhoud behoeft aan het doorvoersysteem.
Beste Alfred,
BeantwoordenVerwijderenhartelijk bedankt voor deze "terug naar de kern" reactie.
Die link ga ik binnenkort eens nader bestuderen.
Overigens, e-depot-monitor-programma, dat klinkt ook interessant. Misschien kun je dat - via een ander medium - eens nader toelichten?
BeantwoordenVerwijderen
BeantwoordenVerwijderenIk vind het fantastisch. Als archivaris ben ik heel erg vóór het inzetten van vakgebieden die ons van oudsher vreemd zijn. Waarop we een totale leek zijn zelfs. Hoe totaal, zal misschien wel blijken uit mijn vraag. Ik blijf hangen aan de volgende zin:
Als je van een geaccepteerd kwaliteitsniveau [ik neem aan: foutenpercentage] van 1% uitgaat, [...] dat er van de 200 items maximaal vijf fout mogen zijn.
Bij mij is 1% van 200 nog altijd twee, en niet vijf. Waarom zegt kaart II dat ik er desalniettemin vijf fout mag hebben? Kan iemand dit statistisch wonder voor mij verduidelijken?
Hartelijke groet,
Mariëtte Rommers
Vakspecialist (ook dat nog) Digitalisering Het Utrechts Archief
Hallo Mariëtte, dank je voor je vraag (ik zie nu ook dat de zin waar je naar verwijst een persoonsvorm mist...)
BeantwoordenVerwijderenDie 200 is de omvang van de steekproef, niet de omvang van de hele te controleren batch. In dit voorbeeld was de omvang van de te controleren batch 5.000 stuks. Een representatieve steekproef daaruit is dan 200 items. En van die 200 items mogen er maximaal 5 fout zijn.
Merk hierbij op dat die 5 min of meer toevallig 1% van 5.000 is. Als de hele te controleren batch 4.000 of 7.000 items was, zouden de steekproefomvang en het maximale foutenaantal even groot zijn (respectievelijk 200 en 5).
Dit heeft aan de ene kant te maken met het begrip representativiteit, die blijkbaar een soort "gemiddelde" is. Aan de andere kant heeft het te maken met afrondingsverschillen. Je kunt geen half item afkeuren.
Ik hoop dat ik dit wonder nu een beetje voor je verklaard heb...
Dag Ingmar! Dank voor je snelle reactie. Ik moet er eens heel erg op gaan broeden, temeer, omdat volgens mij 1% van 5.000 vijftig is, en niet vijf, maar dat is vermoedelijk óók toeval. Ik zal eens kijken of ik een statisticus ergens in vrienden- of familiekring heb. Als ik er toevallig uit zou komen, laat ik het zeker weten.
BeantwoordenVerwijderenGroetjes,
Mariëtte
*Schaamrood* Je hebt natuurlijk helemaal gelijk: 1% van 5.000 is 50...
BeantwoordenVerwijderenIngmar,
BeantwoordenVerwijderenIk heb AQL, op verzoek van een opdrachtgever, voor een bepaalde digitaliseringssituatie uitgewerkt en nou loop ik tegen het volgende aan tav de Operating Characteristics:
Wat is een acceptabel percentage voor batches die ten onrechte goedgekeurd worden?
Ik kom daar niet uit en ik heb het idee dat de norm ook niet zo ver gaat. Je kan wel uitrekenen hoe hoog het percentage is, maar niet hoe je bepaalt wat een acceptabel percentage is. Het lijkt er op dat dat toch weer natte-vinger-werk en persoonlijke voorkeur is.
Eigenlijk is het een voortzetting van de reden om AQL te gebruiken: een logisch-rationele methode om kwaliteit te bepalen. Maar dan op detail-niveau. Een soort Droste-effect.
Zie ik iets over het hoofd? Is er een aanvullende methode?
Ik denk dat deze methode inderdaad niet zo ver gaat en dat het bij het beantwoorden van jouw vraag inderdaad, zoals ik eerder al twitterde, op risico-management aankomt. En dat lijkt, vind ik, vaak op natte vingerwerk.
BeantwoordenVerwijderenWaar het mij bij het schrijven van de tekst hierboven om ging, was dat ik bij heel veel digitaliserings- en vervangingsvoorstellen wel lees dat de foutenmarge x%, maar dat er daarna niet afdoende wordt aangetoond of die x ook wel enigszins gehaald wordt. Hierbij ging ik er dus vanuit dat van te voren al was bedacht dat x acceptabel zou zijn. Bij jouw vraag zou je moeten "uitrekenen" wat het risico is dat je loopt, bij het fout of niet gescand zijn van een document. Dat is heel lastig, zeker als je uit gaat van "erfgoed" aangezien dat "waardeloos" is. Waardeloos in de zin: als het weg is, kun je er niets anders voor in de plaats stellen, dus kun je die kosten ook niet kwantificeren. (Het is een beetje te vergelijken met delen door nul, heb ik wel eens het idee.)Wat je wel zou kunnen doen, is andersom rekenen. Dat je dus uitgaat van de maximale kosten die je bereid bent te maken bij vervanging (en controle-werkzaamheden) en dan uitrekent hoe groot het risico op fouten dan wordt. Als dit betekent dat de kans groot is dat iedere tiende pagina fout is, zou dat ook kunnen betekenen dat je dus niet wil vervangen.
Ik denk er nog wat over na, misschien kunnen we wel een methode uitdenken?
Ingmar en Chido,
BeantwoordenVerwijderenIk heb al eeerder aangehaald dat BCT op mijn aandringen bezig was een kwaliteitsmodule te ontwikkelen voor het kunnen meten van fouten tijdens of na scanjobs. Zeer recent heb ik een demonstratie gehad van BCT van de betreffende kwaliteitsmodule. Deze is geheel ontwikkeld op basis van de ISO 2859 norm. inclusief de tabellen die daaronder vallen ten aanzien van de bepaling van de te meten hoeveelheden.
In mijn bescheiden optiek is dit een zeer bruikbare module geworden die het zijn gebruikers op heel eenvoudige wijze mogelijk maakt een gedegen kwaliteitsborgingsmethodiek toe te passen en de resultaten daarvan ook vast te leggen.
De module zal als zelfstandige softwaretool ook ingezet kunnen worden voor toepassingen anders dan Corsa.
Voorzover ik weet is dit de eerste keer dat een bruikbare tool kan worden ingezet specifiek in het segment van document digitalisering.
Is het wellicht een idee om een meeting te organiseren waar een groter aantal deskundigen met elkaar de module kunnen beoordelen en te bespreken in hoeverre dit een antwoord geeft op de in deze discussie gestelde vragen.
Ik denk dat we met deze software heel ver zullen kunnen komen.
met vriendelijke groet
Leon van Oosterom, Elveo b.v.
Eindelijk toe gekomen om er zelf een blogje over te schrijven: http://chido-advies.blogspot.nl/2012/11/archiefje-digitaliseren-over-aql.html
BeantwoordenVerwijderen